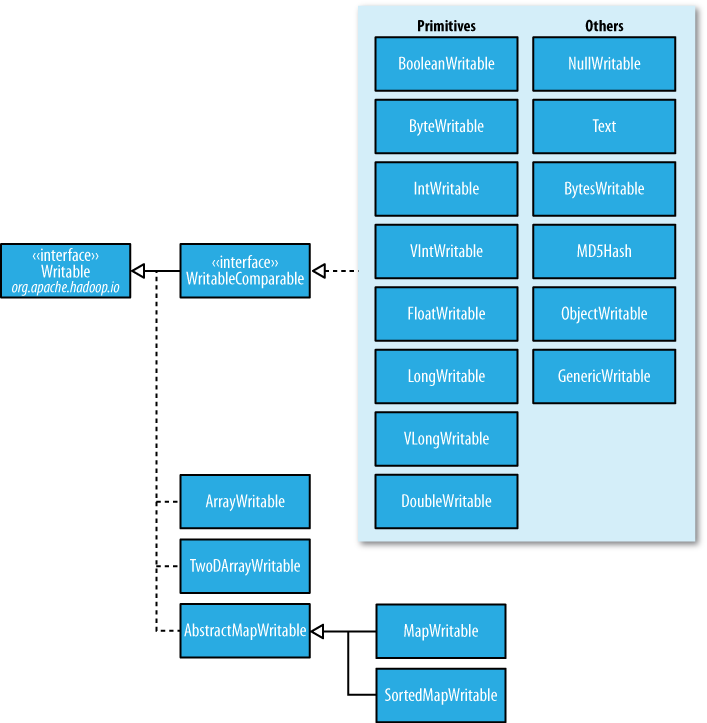
packageorg.apache.hadoop.io;importjava.io.DataOutput;importjava.io.DataInput;importjava.io.IOException;publicinterfaceWritable{/** * Serialize the fields of this object to <code>out</code>. * * @param out <code>DataOuput</code> to serialize this object into. * @throws IOException */voidwrite(DataOutputout)throwsIOException;/** * Deserialize the fields of this object from <code>in</code>. * * <p>For efficiency, implementations should attempt to re-use storage in the * existing object where possible.</p> * * @param in <code>DataInput</code> to deseriablize this object from. * @throws IOException */voidreadFields(DataInputin)throwsIOException;}
packagecom.yoyzhou.weibo;importjava.io.DataInput;importjava.io.DataOutput;importjava.io.IOException;importorg.apache.hadoop.io.VLongWritable;importorg.apache.hadoop.io.Writable;/** *This MyWritable class demonstrates how to write a custom Writable class * **/publicclassMyWritableimplementsWritable{privateVLongWritablefield1;privateVLongWritablefield2;publicMyWritable(){this.set(newVLongWritable(),newVLongWritable());}publicMyWritable(VLongWritablefld1,VLongWritablefld2){this.set(fld1,fld2);}publicvoidset(VLongWritablefld1,VLongWritablefld2){//make sure the smaller field is always put as field1if(fld1.get()<=fld2.get()){this.field1=fld1;this.field2=fld2;}else{this.field1=fld2;this.field2=fld1;}}//How to write and read MyWritable fields from DataOutput and DataInput stream@Overridepublicvoidwrite(DataOutputout)throwsIOException{field1.write(out);field2.write(out);}@OverridepublicvoidreadFields(DataInputin)throwsIOException{field1.readFields(in);field2.readFields(in);}/** Returns true if <code>o</code> is a MyWritable with the same values. */@Overridepublicbooleanequals(Objecto){if(!(oinstanceofMyWritable))returnfalse;MyWritableother=(MyWritable)o;returnfield1.equals(other.field1)&&field2.equals(other.field2);}@OverridepublicinthashCode(){returnfield1.hashCode()*163+field2.hashCode();}@OverridepublicStringtoString(){returnfield1.toString()+"\t"+field2.toString();}}
未完待续,下一篇中将介绍Writable对象序列化为字节流时占用的字节长度以及其字节序列的构成。
参考资料
Tom White, Hadoop: The Definitive Guide, 3rd Edition